
frida+d3mug复现
FRIDA-API使用篇
frida中有五种对象,分别是Java、Interceptor、NativePointer、NativeFunction、NativeCallback对象
这些都是在编写frida脚本的时候会用到的对象以及对应的函数。
frida知识更多的学习,可以查看这些文章
Java对象
无论是想对so层亦或java层进行拦截,都必须编写Java.perform,java对象是很重要的
附加调用Java.perform
Java.perform(fn)主要用于当前线程附加到Java VM并且调用fn方法。该API是非常重要的
示例:
1 | unction frida_Java() { |
判断加载Java.available
该函数一般用来判断当前进程是否加载了**JavaVM,Dalvik或ART虚拟机**
示例:
1 | function frida_Java() { |
版本号Java.androidVersion
显示android系统版本号
示例:
1 | function frida_Java() { |
获取类Java.use
Java.use(className),动态获取className的类定义,通过对其调用$new()来调用构造函数,可以从中实例化对象。当想要回收类时可以调用$Dispose()方法显式释放,当然也可以等待JavaScript的垃圾回收机制,当实例化一个对象之后,可以通过其实例对象调用类中的静态或非静态的方法
示例:
1 | Java.perform(function () { |
枚举类Java.enumerateLoadedClasses
该API枚举当前加载的所有类信息,它有一个回调函数分别是onMatch、onComplete函数
1 | function frida_Java() { |
扫描实例类Java.choose
在堆上查找实例化的对象,实例化对象的意思就是用这个类创建的一个对象(如同人这个类中的叫小明的这个人)
1 | Java.perform(function () { |
类型转换器Java.cast
使用 Java.cast(object,Class) 可以转换一个对象的类型。通常在拦截so层时会使用此函数将jstring、jarray等等转换之后查看其值。
示例:
1 | Java.performNow(function () { |
定义任意数组类型Java.array
frida提供了在js代码中定义java数组的api,该数组可以用于传递给java API。定义格式为Java.array('type',[value1,value2,....]);
示例:
1 | Java.perform(function () { |
Java.vm对象
Java.vm对象十分常用,比如想要拿到JNI层的JNIEnv对象,可以使用**getEnv()**。
1 | function frida_Java() { |
Interceptor对象
函数原型是**Interceptor.attach(target, callbacks)**:
target参数:是需要拦截的位置的函数地址,也就是填某个**so层函数的地址即可对其拦截,target是一个NativePointer参数**,用来指定你想要拦截的函数的地址,NativePointer是一个指针(下面有对NativePointer的说明);对于Thumb函数需要对函数地址+1
callbacks参数:它的回调函数,有两个onEnter: function (args) 和 onLeave: function (retval)函数
Interceptor.attach
两个回调函数:
onEnter:函数(args):回调函数,给定一个参数args,可用于读取或写入参数作为NativePointer对象的数组。onLeave:函数(retval):回调函数给定一个参数retval,该参数是包含原始返回值的NativePointer派生对象。可以调用retval.replace(1337)以整数1337替换返回值,或者调用retval.replace(ptr("0x1234"))以替换为指针。
示例:
1 | //使用Module对象getExportByNameAPI直接获取libc.so中的导出函数read的地址,对read函数进行附加拦截 |
Interceptor.attach函数的一些属性:
returnAddress 返回地址,类型是 NativePointerthreadId 操作系统线程ID context 上下文:具有键 pc和sp的对象,它们是分别为ia32/x64/arm指定EIP/RIP/PC和ESP/RSP/SP的NativePointer对象。其他处理器特定的键也可用,例如eax、rax、r0、x0等。也可以通过分配给这些键来更新寄存器值。errno 当前 errno值lastError 当前操作系统错误值 depth 相对于其他调用的调用深度
示例:
1 | Interceptor.attach(Module.findExportByName("libhello.so" , "Java_com_roysue_roysueapplication_hellojni_getSum"), { |
Interceptor.detachAll
简单来说这个的函数的作用就是让之前所有的Interceptor.attach附加拦截的回调函数失效
Interceptor.replace
相当于替换掉原本的函数,用替换时的实现替换目标处的函数。如果想要完全或部分替换现有函数的实现,则通常使用此函数。
示例:
1 | function frida_Interceptor() { |
NativePointer对象
同等与C语言中的指针
new NativePointer(s)
声明定义NativePointer类型
1 | const ptr1 = new NativePointer("100"); |
运算符以及指针读写API
这里有个表,可以用这个指针对这些API进行调用


示例:
1 | // 用readByteArray函数来读取libc.so文件在内存中的数据 |
上面这些API的调用的部分示例可以查看这篇文章中的NativePointer对象这个部分
NativeFunction对象
作用:调用address处的函数(用NativePointer指定)
函数定义格式:new NativeFunction(address, returnType, argTypes[, options])
- returnType和argTypes[,]中能够填写的数据类型:void、pointer、int、uint、long、ulong、char、uchar、float、double、int8、uint8、int16、uint16、int32、uint32、int64、uint64这些类型。假设有三个参数都是
int,则new NativeFunction(address, returnType, [‘int’, ‘int’, ‘int’]) - 定义的时候必须要将参数类型个数和参数类型以及返回值完全匹配。
- 并且第一个参数一定要是函数地址指针
示例:
1 | // LargeObject HandyClass::friendlyFunctionName(); |
NativeCallback对象
作用:创建一个回调函数
函数定义格式:new NativeCallback(func,rereturn Type,argTypes[,ABI])
- func参数:由JavaScript函数实现的函数
rereturn Type指定返回类型,argTypes数组指定参数类型
当将产生的回调与Interceptor.replace()一起使用时,将调用func,并将其绑定到具有一些有用属性的对象,就像Interceptor.Attach()中的那样
示例:
1 | Java.perform(function () { |
使用java.perform()中写入js脚本
使用Module对象获得一些so文件的地址信息
利用so文件的地址信息使用NativeFunction 得到so文件之中的对象,再使用Interceptor对象的API,对相应的函数进行一定的操作
运行这个函数,设置这个函数的输入的参数,设置这个函数的返回的参数
FRIDA-API使用篇:rpc、Process、Module、Memory
这里对frida官方的一些非常常用的API进行介绍
FRIDA输出打印
在官方API有两种打印的方式,分别是console、send
console输出
在FRIDA的console中有三个级别分别是log、warn、error。一般在使用中我们只会使用log来输出想看的值。
1 | function hello_printf() { |
console之hexdump
hexdump的含义:打印内存中的地址,target参数可以是ArrayBuffer或者NativePointer,而options参数则是自定义输出格式可以填这几个参数offset、lengt、header、ansi
示例:
1 | var libc = Module.findBaseAddress('libc.so'); |
执行效果:
1 | 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF |
send
原理:send是在python层定义的on_message回调函数,jscode内所有的信息都被监控script.on(‘message’, on_message),当输出信息的时候on_message函数会拿到其数据再通过format转换、
输出效果:能够直接将数据以**json格式**输出,当然数据是二进制的时候也依然是可以使用send
示例:
1 | import frida |
效果:
1 | roysue@ubuntu:~/Desktop/Chap09$ python Chap03.py |
FRIDA变量类型
在脚本之中如何声明变量类型。以及frida为Int64(v)提供了一些相关的API的使用
声明变量类型
| 索引 | API | 含义 |
|---|---|---|
| 1 | new Int64(v) | 定义一个有符号Int64类型的变量值为v,参数v可以是字符串或者以0x开头的的十六进制值 |
| 2 | new UInt64(v) | 定义一个无符号Int64类型的变量值为v,参数v可以是字符串或者以0x开头的的十六进制值 |
| 3 | new NativePointer(s) | 定义一个指针,指针地址为s |
| 4 | ptr(“0”) | 同上 |
示例:
1 | Java.perform(function () { |
Int64(v)使用的API
| 索引 | API | 含义 |
|---|---|---|
| 1 | add(rhs)、sub(rhs)、and(rhs)、or(rhs)、xor(rhs) | 加、减、逻辑运算 |
| 2 | shr(N)、shl(n) | 向右/向左移位n位生成新的Int64 |
| 3 | Compare(Rhs) | 返回整数比较结果 |
| 4 | toNumber() | 转换为数字 |
| 5 | toString([radix=10]) | 转换为可选基数的字符串(默认为10) |
示例:
1 | function hello_type() { |
Process对象
介绍以及使用一些Process对象中比较常用的api
Process.id
Process.id:返回附加目标进程的PID
Process.isDebuggerAttached()
检测当前是否对目标程序已经附加
Process.enumerateModules()
枚举当前加载的模块,返回模块对象的数组。会枚举当前所有已加载的so模块,并且返回了数组Module对象。
枚举得到的每个module对象,再使用每个module对象进行操作
1 | function frida_Process() { |
Process.enumerateThreads()
枚举当前所有的线程,返回包含以下属性的对象数组:
| 索引 | 属性 | 含义 |
|---|---|---|
| 1 | id | 线程id |
| 2 | state | 当前运行状态有running, stopped, waiting, uninterruptible or halted |
| 3 | context | 带有键pc和sp的对象,它们是分别为ia32/x64/arm指定EIP/RIP/PC和ESP/RSP/SP的NativePointer对象。也可以使用其他处理器特定的密钥,例如eax、rax、r0、x0等。 |
Process.getCurrentThreadId()
获取此线程的操作系统特定 ID 作为数字
Module对象
获得程序中函数 类等的一些信息的时候(基地址,偏移地址等)就会用到这个对象
Module对象的属性
| 索引 | 属性 | 含义 |
|---|---|---|
| 1 | name | 模块名称 |
| 2 | base | 模块地址,其变量类型为NativePointer |
| 3 | size | 大小 |
| 4 | path | 完整文件系统路径 |
Module对象的API
| 索引 | API | 含义 |
|---|---|---|
| 1 | Module.load() | 加载指定so文件,返回一个Module对象 |
| 2 | enumerateImports() | 枚举所有Import库函数,返回Module数组对象 |
| 3 | enumerateExports() | 枚举所有Export库函数,返回Module数组对象 |
| 4 | enumerateSymbols() | 枚举所有Symbol库函数,返回Module数组对象 |
| 5 | Module.findExportByName(exportName)、Module.getExportByName(exportName) | 寻找指定so中export库中的函数地址 |
| 6 | Module.findBaseAddress(name)、Module.getBaseAddress(name) | 返回so的基地址 |
enumerateImports()
该API会枚举模块中所有中的所有Import函数
1 | const hooks = Module.load('libhello.so'); |
enumerateExports()
该API会枚举模块中所有中的所有Export函数
1 | const hooks = Module.load('libhello.so'); |
enumerateSymbols()
该API会枚举模块中所有中的所有symbols 符号,使用symbols 符号可以定位native方法。返回的是一个数组对象
1 | const hooks = Module.load('libc.so'); |
Module.findExportByName(exportName), Module.getExportByName(exportName)
返回so文件中Export函数库中函数名称为**exportName函数的绝对地址**
这个方法只适用于Export函数
1 | Module.getExportByName('libhello.so', 'c_getStr') |
Module.findBaseAddress(name)、Module.getBaseAddress(name)
返回name模块的基地址
示例:
1 | var name = "libhello.so"; |
Memory对象
Memory的一些API的作用:通常是对内存处理,譬如Memory.copy()复制内存
Memory.scan搜索内存数据
功能:搜索内存中以address地址开始,搜索长度为size,需要搜是条件是pattern,callbacks搜索之后的回调函数
格式:Memory.scan(module.base, module.size, pattern,callbacks)
示例:
1 | Java.perform(function () { |
内存分配Memory.alloc
作用:在目标进程中的堆上申请size大小的内存,并且会按照Process.pageSize对齐,返回一个NativePointer,并且申请的内存如果在JavaScript里面没有对这个内存的使用的时候会自动释放的。
1 | const r = Memory.alloc(10); |
内存复制Memory.copy
示例:
1 | //申请一个内存空间大小为10个字节 |
写入内存Memory.writeByteArray’
将字节数组写入一个指定内存
示例:
1 | //定义需要写入的字节数组 这个字节数组是字符串"roysue"的十六进制 |
读取内存Memory.readByteArray
这个函数的第一个参数传入的是 NativePointer 类型的地址指针
1 | //读取r指针,长度是arr.length 也就是会打印上面一样的值 |
参考文章:FRIDA-API使用篇:rpc、Process、Module、Memory使用方法及示例 - 安全客
frida的so函数hook
so文件之中的函数有导出函数和非导出函数,导出函数打开IDA后能够在导出表中找到的函数就是导出函数,未导出函数则在导出表中寻找不到。一般来说静态编写的native函数都能在导出表中寻找到,而动态加载的则无法在导出表中发现
在IDA的Exports页面之中查看导出函数窗口
示例:
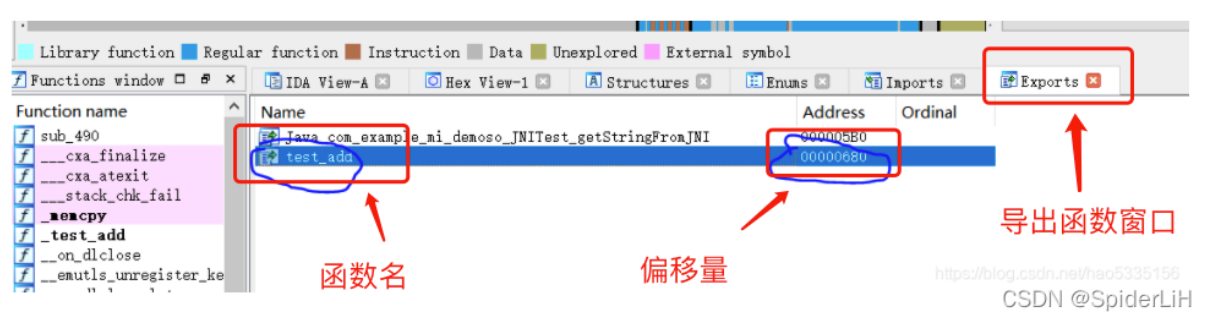
导出函数hook:导出函数窗口可以看到导出函数的函数名,偏移量 。导出函数的hook可以通过函数名或者偏移量。
非导出函数hook:只能通过地址hook。定位到函数的位置,直接看它的偏移量即可
通过函数地址获取指定 so 文件的函数
函数地址 = so基地址 + 函数偏移(如果Thumb 指令, hook 的偏移地址需要进行 +1 操作)
IDA 判断 Thumb 指令集和 Arm指令集
- IDA - Options - General - number of opcode bytes - 设置为 4
- 此时查看 IDA VIew 中 opcode 的长度, 如果出现 2 个字节和 4 个字节的, 说明为 thumb 指令集
- 如果都是 4 个字节的, 说明是 arm 指令集;
- 在 Thumb 指令集下, inline hook 的偏移地址需要进行 +1 操作;
1 | var str_name_so = "libjnitest.so"; //需要hook的so名 |
通过函数名获取指定 so 文件的函数
1 | var ptr_func = Module.findExportByName("libjnitest.so","test_add") //对函数名hook |
通过 symbols 符号定位 native 方法
1 | var NewStringUTF_addr = null; |
通过 Intercept 拦截器打印 native 方法参数和返回值, 并修改返回值
1 | var add_c_addr = Module.findExportByName("libnative-lib.so", "add_c"); |
获取指定 so 文件的基地址
1 | var baseAddr = Module.findBaseAddress("libnative-lib.so"); |
Hook修改native层函数返回值为int类型的情况
使用replace()函数直接修改即可
frida脚本示例:
1 | import frida |
Hook修改native层函数返回值为string类型
返回值为字符串其实是返回了一个char \*(字符串指针),所以简单的替换是无法取效果的
关键代码:
1 | var env = Java.vm.getEnv(); //获取env对象,也就是native函数的第一个参数 |
示例
1 | import frida |
Frida命令
基础命令
1 | # 启动frida-server(模拟器) |
d3mug
ctf之中的游戏逆向(unity3D逆向分析)
unity逆向的文章(里面有各种各样的有关unity的题目,可以学习一下):https://forum.butian.net/share/1294
unity游戏IL2CPP类型
这道题是 :IL2CPP类型相对来说,题目难度有一个质的提升。对unity的理解程度需要更深。IL2CPP的Unity3D游戏的逆向,只需要根据global-metadata.dat和libil2cpp.so来进行就可以了。
il2cpp的内部实现文档:https://blogs.unity3d.com/2015/05/06/an-introduction-to-ilcpp-internals/
il2cpp(主要分析metadata的一篇文章)
游戏的主页面

游戏的运行界面:需要在白线的上面不停的点击这些蓝色的模块,如果能在白线的位置上点击到,那么GOOD就会增加一
IL2CPPDumper
使用IL2CPPDumper这个工具将apk解包之后的global-metadata.dat和libil2cpp.so这两个文件,dump出该DLL里的所有类以及类里的方法和成员,
使用IL2CPPDumper这个工具dump的方法以及dump出来的文件说明
dump(input文件)

dump(output文件)

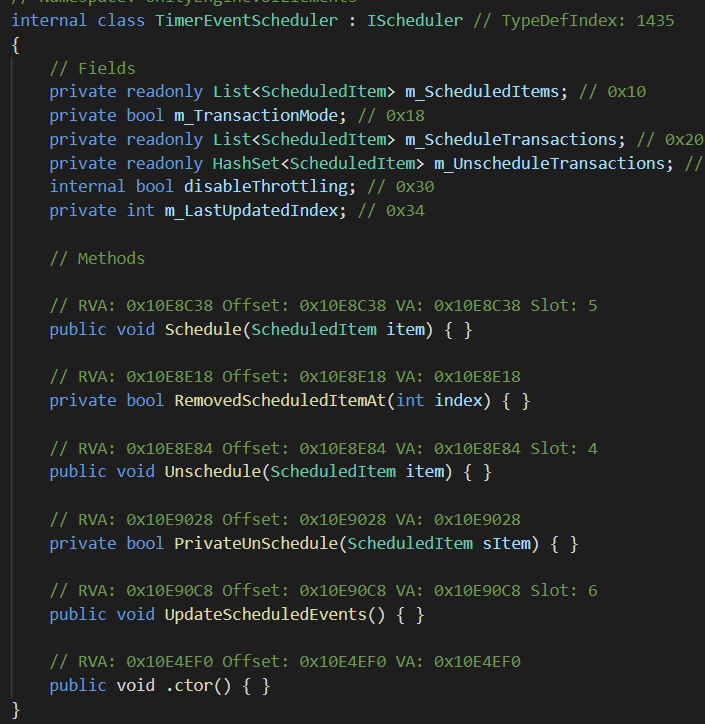
dump.cs:
这个文件会把C#的dll代码的类、方法、字段列出来。这里面有非常多的数据
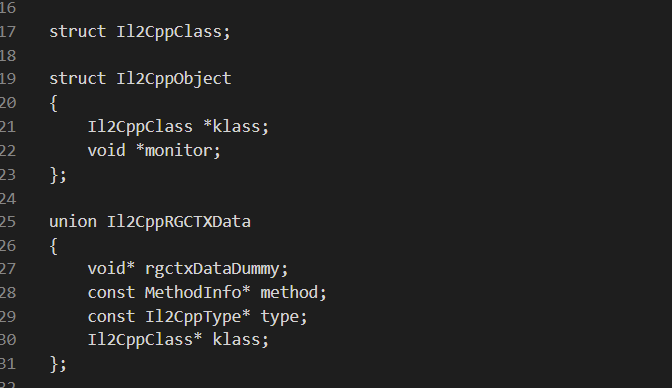
il2cpp.h:
生成的cpp的头文件,从头文件里我们也可以看到相关的数据结构
script.json:
以json格式显示类的方法信息
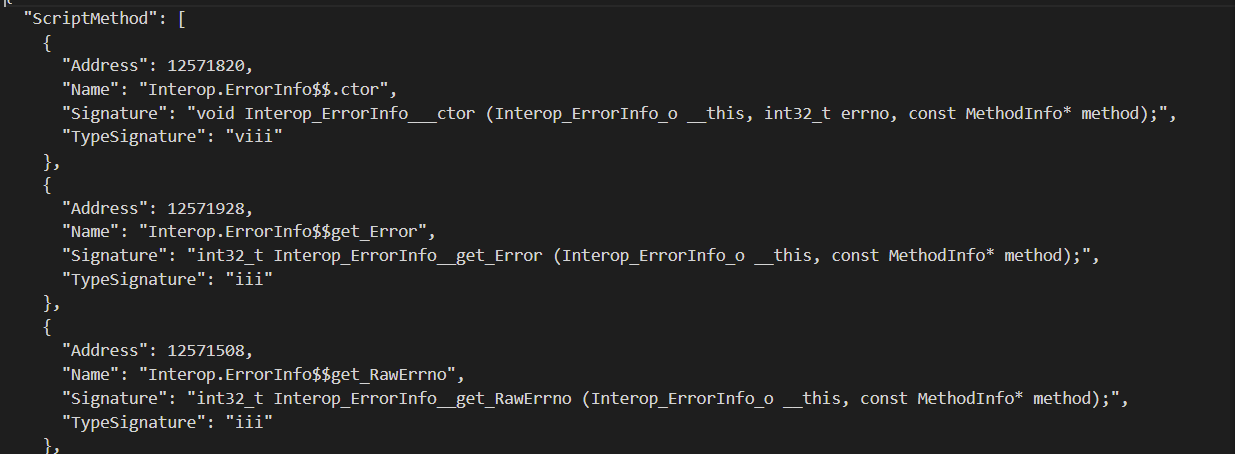
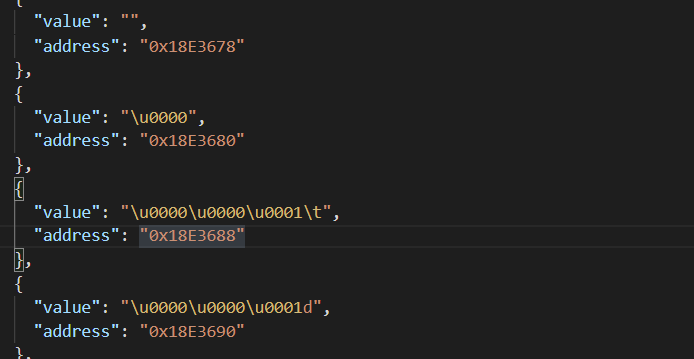
stringliteral.json:
以json的格式显示所有的字符串信息
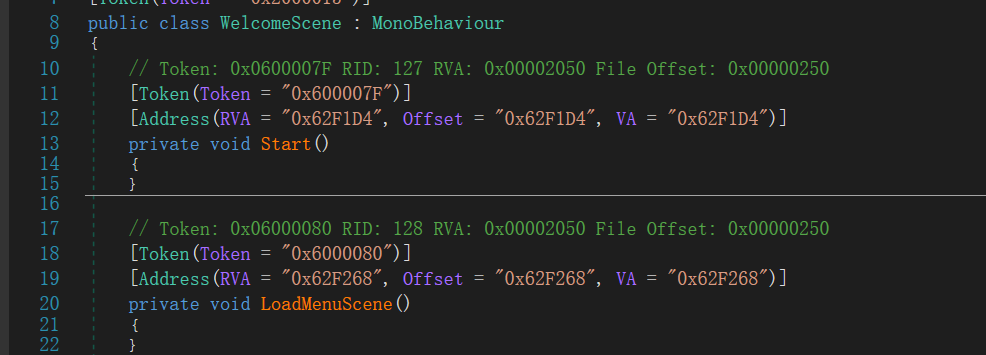
DummyDll/Assembly-CSharp.dll
进入DummyDll目录,可以看到很多dll,其中就有Assembly-CSharp.dll,使用dnspy打开这个文件
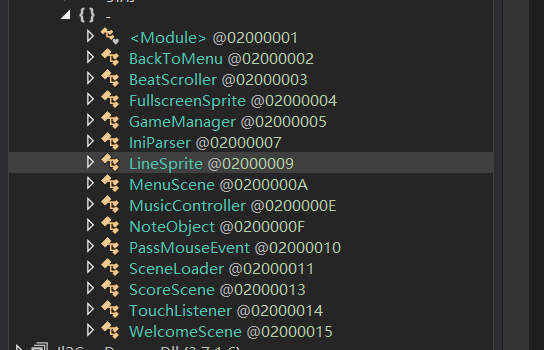
文件列表:可以看到这里是游戏页面的初始化,组件(线),音乐等等
从上面IL2CppDumper我们可以发现,逆向得到的函数体都是空的,看不了内部逻辑。内部的逻辑结构就需要使用IDA查看libil2cpp.so这个文件,在这个文件中使用上面得到的cs文件的偏移量找到目标的函数
关键函数定位
将Il2CppDumper 处理之后得到的Assembly-CSharp.dll文件放入到dnspy之中,这个文件里面存放了这个游戏里面函数的偏移地址
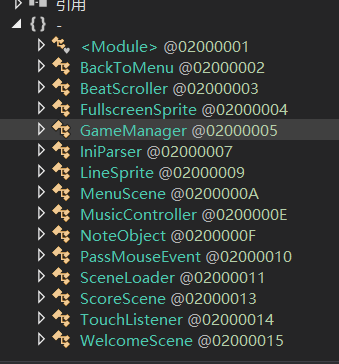
根据需要查看相应的类,再查看相应的类中的函数的偏移地址
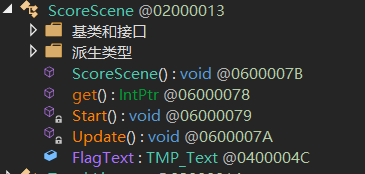
这里我们需要查看 GameManager和 ScoreScene类中的函数
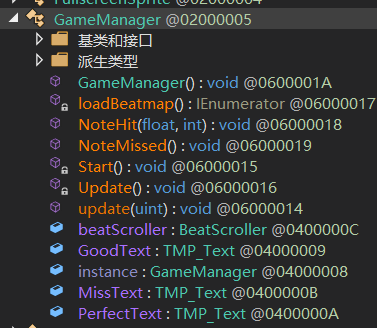
游戏逻辑分析
使用上面得到的Assembly-CSharp.dll文件定位到函数的关键地址
NoteObject类中的OnClicked()函数
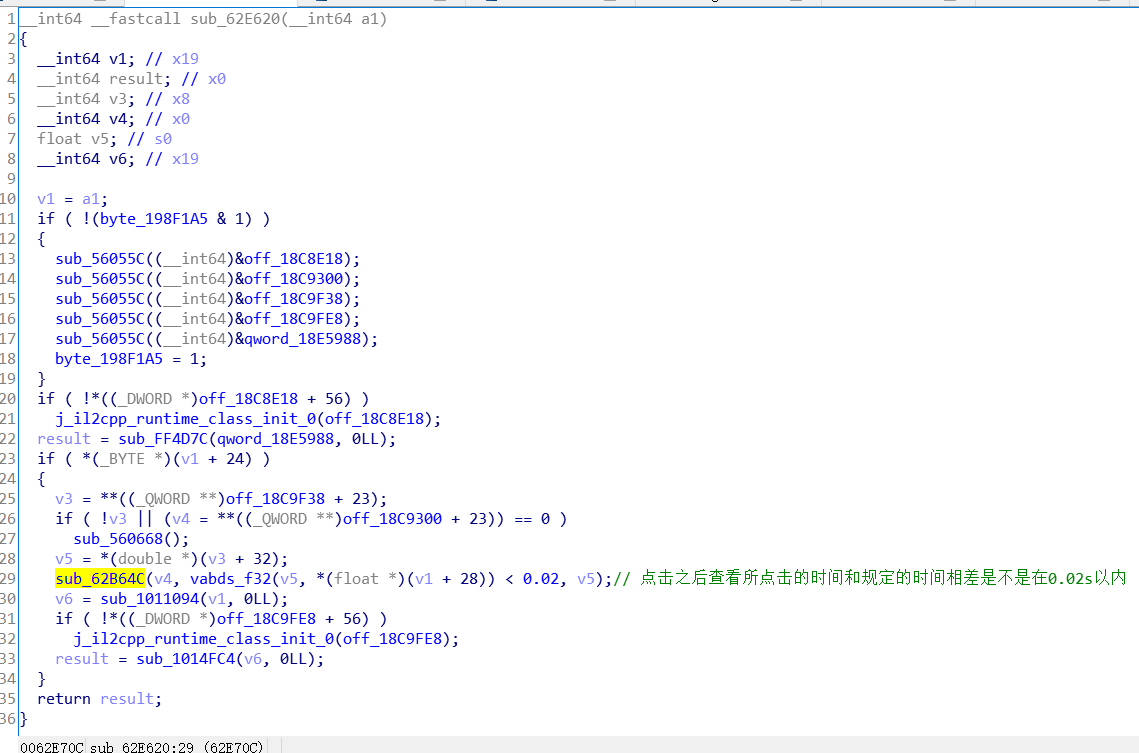
再跟进这个判断时间的函数之中 它的rva是RVA = “0x62B64C” ,查看Assembly-CSharp.dll这个文件我们可以知道它就是NoteHit()函数
GameManager类的NoteHit()函数
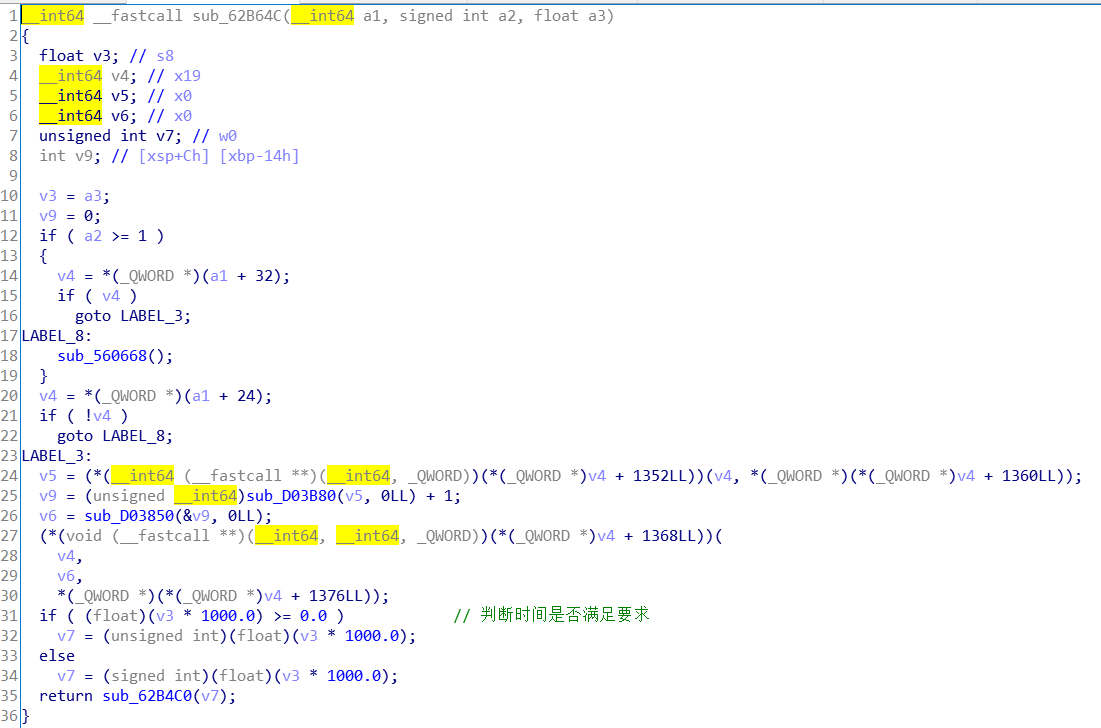
GameManager类中的update()函数
从上面那张图中可以得到在NoteHit()函数的结尾的地方调用了update()函数
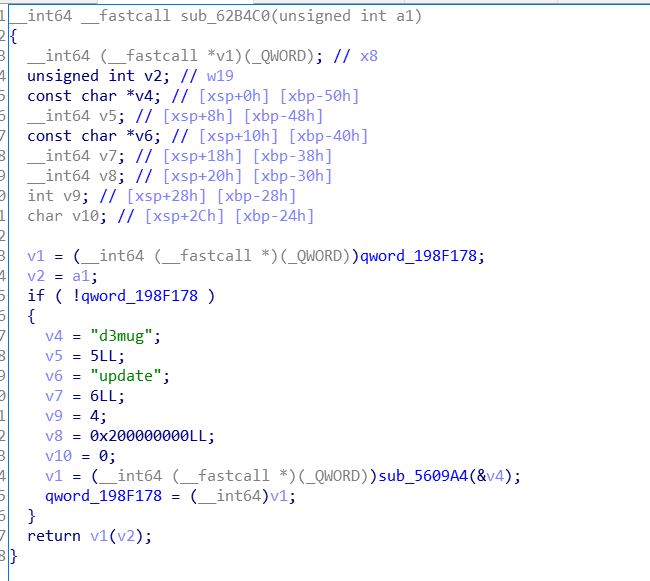
上面这个update()函数调用了libd3mug.so的update()函数,这个函数的最后调用了server.run

逻辑分析:点击了NodeObject是表示音游之中的方块的类,NoteObject类中的OnClicked()函数表示点击方块,之后会触发GameManager类的NoteHit()函数分析点击的时间,从而确定是否点击成功与否,该函数之后会调用GameManager类中的update()函数
然后查看分数的模块ScoreScene类
ScoreScene类的get()函数
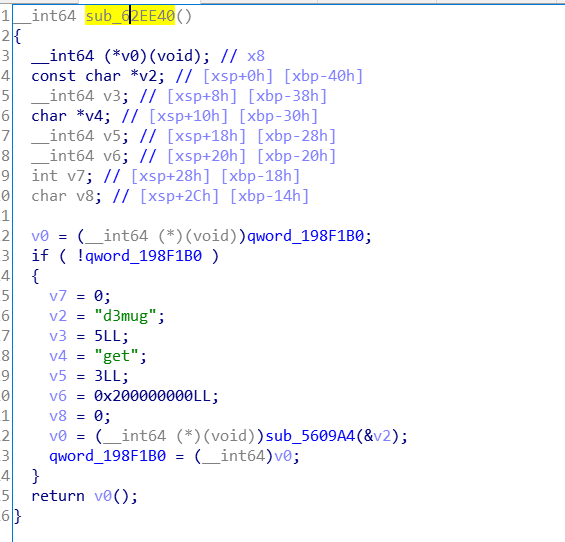
上面这个get()函数里面调用了libd3mug.so中的get()函数
libd3mug.so中的get()函数

通过这个函数交叉查询一下,找到引用该函数的函数sub_62EE40() 它便是ScoreScene类的Start()函数
ScoreScene类的Start()函数
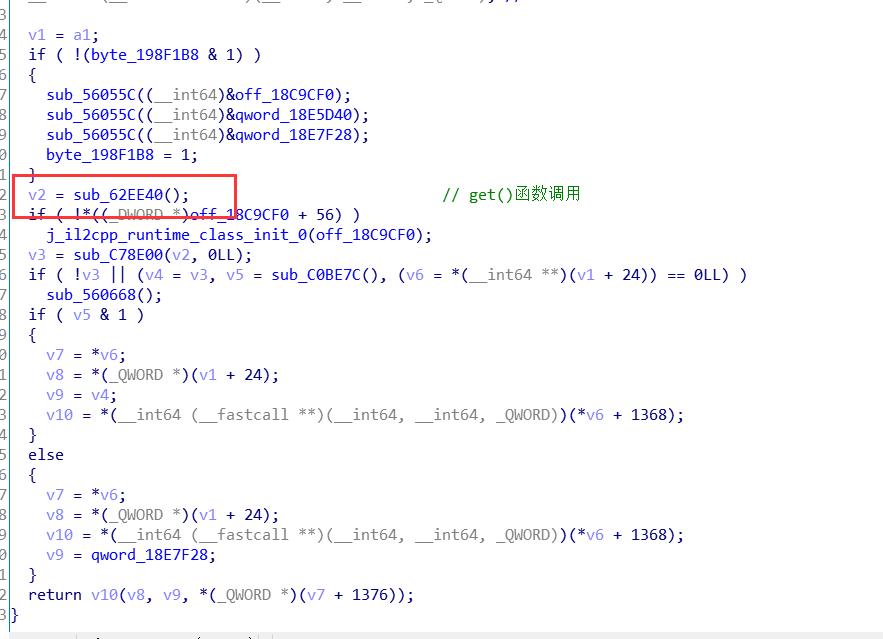
逻辑分析:游戏结束之后会转到的类是ScoreScene类,其中最后显示分数的函数中,调用了get()函数,这样获得了一个字符串
AssertStudio获得谱面
这是一个音游的游戏,由于需要我们踩点正确,所以就要我们找到这个游戏中的谱面(音乐的谱子),使用AssertStudio Unity解包提取资源/AssetStudio的简单使用_咲奈的平行时空-CSDN博客_unity解包](https://blog.csdn.net/qq_21567385/article/details/107015800))加载这个unity游戏的assets目录,在它的Asset List下面我们能够看到很多资源文件,其中的hitpoints的文件就是它的谱面
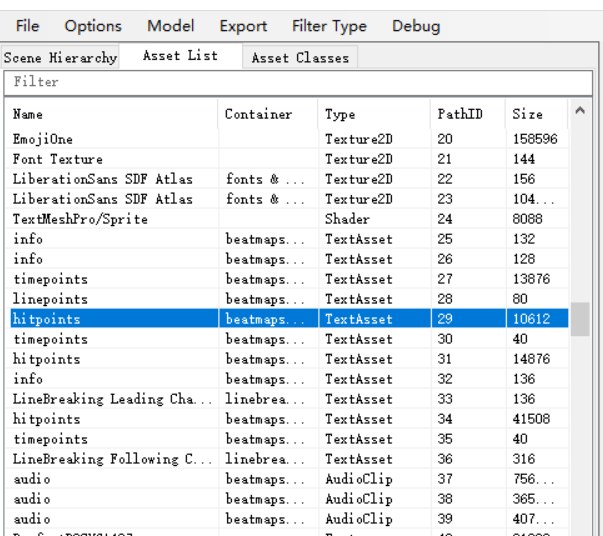
在这个游戏页面的首页之中我们就能够看到这个游戏的音乐是 Chromevox
这里有三个音乐的hitpoints 我们选择其中是Chromevox的

将这个文件导出出来,这个文件之中前面表示的是轨道数,后面表示的是时间

按照之前的方法找到GameManager类的NoteMissed()函数
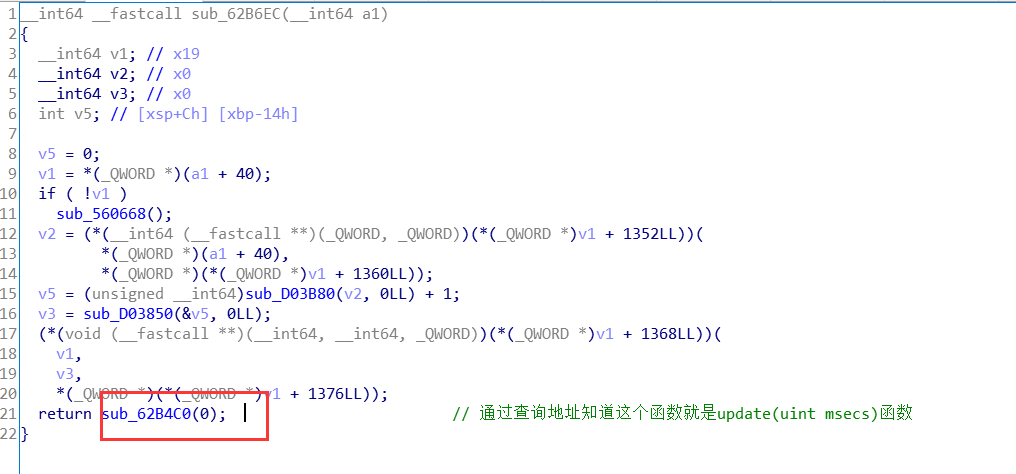

从图中我们可以知道update()中的参数就是msecs,所以我们需要将得到的hitpoints中的msecs作为 参数传入其中,这个过程就需要frida来hook函数
frida
查看frida-server是否成功开启,-U表示USB,允许Frida检查USB设备,这时将看到一个进程列表。
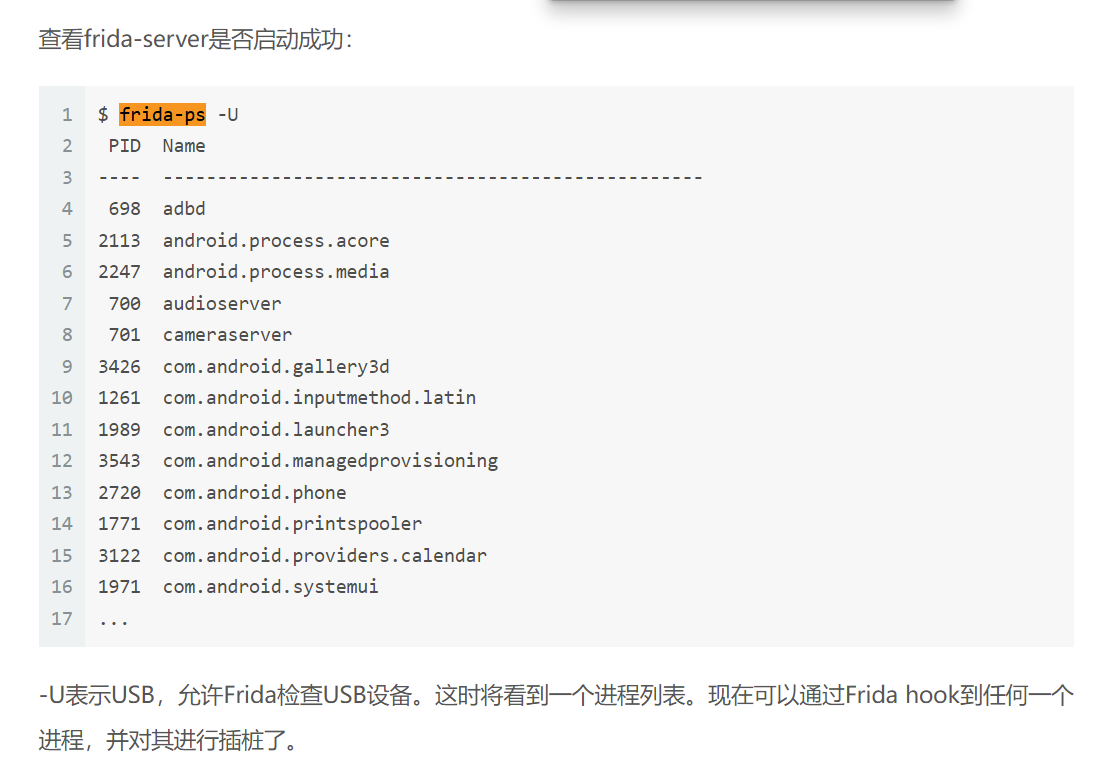
通过该命令可以得到frida脚本中所需要的文件信息(pid 和 应用名和包名)
脚本
1 | import frida, sys |
D3CTF{Gb78e-7b04-4364-82d2-7f44}
如果用解密的方法从libd3mug.so函数分析加密的结果得到flag的脚本
官方的解释:libd3mug.so中的算法是一个类似于feistel的东西,通过一个静态的种子初始化
mt19937随机数生成器,然后先生成随机数判定是否要进入下一步解密,在解密中重新生成随机数作为key,然后选取
一个偏移在数据中取出32字节,加密其中的16字节并将左右位置互换,将每个note的击打时间都录入update函数,即
可解出正确答案。
1 | #include <stdio.h> |
最后得到flag:D3CTF{Gb78e-7b04-4364-82d2-7f44}
