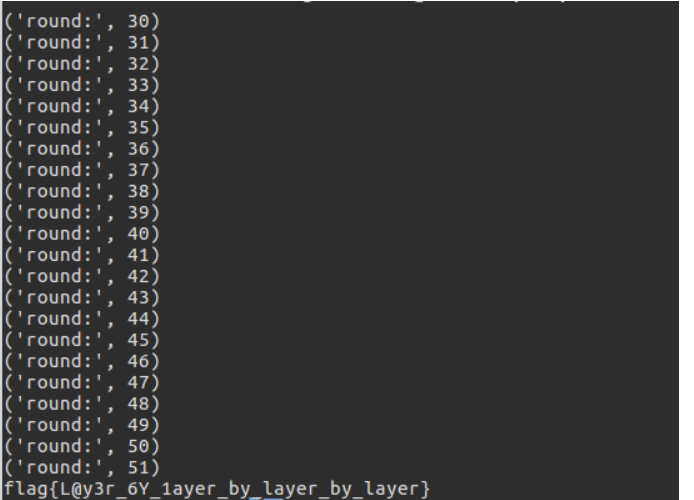
DASCTF_Oct
DASCTF_Oct_re
这两道题中都有加密的知识点,第一道题的SM4的解密在最后一步仍然有问题,希望大佬能够指点指点(●’◡’●)
马猴烧酒
知识点:
- 魔改SM4
- 魔改base64
用ida6将文件载入其中

定位到相应的代码的位置,这段代码开始的位置就有一段flag{this_is_fake_flag}的flag
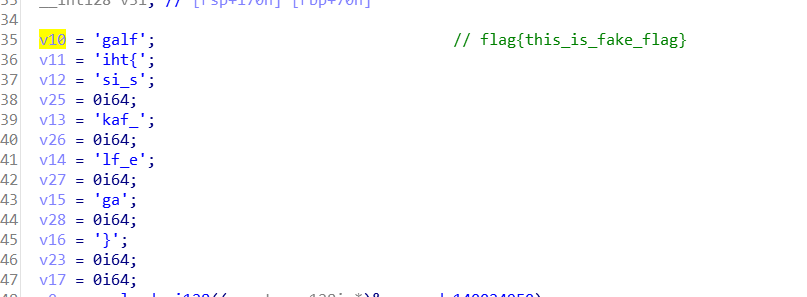
密钥的生成
第一个函数是获取时间戳,第二个函数是对时间戳base64的变表加密,第三个异或运算得到密钥
获取时间戳
使用0x61624B82 演变得到一串数组

脚本:
1 | key = 0x61624B82 |
魔改的base64加密
用标准的base64加密这个字符串的结果是 MTYzMzgzMTgxMA==
分析本代码之中的base64加密 可以知道如果位数不是3的倍数位也是使用“=”
base64的变表
1 | abcdefghijklmnopqrstuvwxyz0123456789+/ABCDEFGHIJKLMNOPQRSTUVWXYZ= |
利用base64的变表和标准表的对应关系得到该代码base64加密的结果
1 | oldkey = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' |


异或运算
将上面base64的加密结果和字符串 “flag{this_is_fake_flag}”进行异或运算
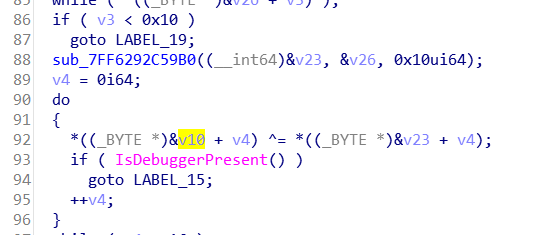
脚本(密钥):
1 | tem1 = 'mtyNmN6Nmt6Lma==' |
得到的这个数组将会作为SM4加密的key
SM4加密
- 识别出SM4加密
- 找到SM4加密魔改的地方
加密之后的结果和相应的数组对比

需要解密的对象是:
1 | enc = [0xf7,0xeb,0x5e,0x87,0x17,0x9c,0x74,0x94,0x44,0xb5,0xf5,0x12,0xf9,0x74,0x15,0x5f] |
轮函数每次会处理128bite的数据,会将这128bite的数据分成4个32bite的数据
SM4加密,每组加密的是128bit,每32bit加密之后的顺序发生了变化的

对每个8bit都用了s盒进行了处理,在内存之中找到s盒是
1 | { |
SM4解密脚本
网上找一个SM4的c语言脚本,修改里面的Sbox,CK参数,以及将上面得到的key和解密的对象引入(但是我从网上找了两个解密的脚本,修改了里面相应的参数之后,仍然得不到想要的结果,并且在内存之中也没能找到修改之后的CK参数,希望指点指点)
SM.h头部文件
1 |
|
main.cpp
1 | #include <stdio.h> |
结果:
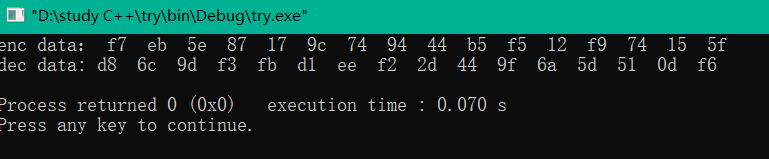
misc DASCTF Oct X writeup | jxswcy’s blog
魔法叠加
知识点:
- pyc文件头部(py3.7)
- base91解密
修改pyc头部
文件头部修改成如图所示 这里是python3.7
这个pyc是python3.7的版本 ,所以修改magic头部为 42 0D,后面34 改为32,因为要减去两个多出来的字节
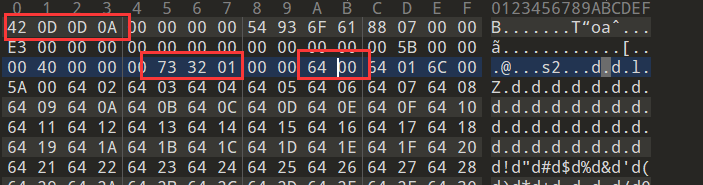
在网上找到一个pyc的文件头部(对比着来修改)
unemployee6反编译
修改完pyc的文件头部之后,用unemployee6进行反编译(看到下面的命名方式,可以自行修改一下命名)
1 | # uncompyle6 version 3.8.1.dev0 |
上面给的数组的长度是91 并且每次模的对象也是91,所以这里应该是[base91](aberaud/base91-python: A python implementation of Base91 as described on http://base91.sourceforge.net/ (github.com))
整理得到
1 | import struct |
base91的解密
加密解密base91的官方文档(注意每个函数参数类型)
1 | import struct |
通过上面的循环我们可以知道一共进行了52次循环,所以利用对应每次变换得到的表进行每次的base91的解密
脚本:
1 | import struct |
注意byte 和 石头人相互转换的方法:
1 | # str to bytes |
因为解密的长度太长了,所以就直接用别人跑出来的结果