
starCTF2022_Simple+NaCl
Simple_File_System
这道题当时卡在这里就是不知道存放的数据在哪里,结果后来发现就是在image.flag文件之中(被自己蠢哭了!!!!)
数据提取
将程序运行一遍,将加密之后的文本的内容写入一个文件之中,再将这个文件放入010之中,提取前5个字节的内容,也就是 *CTF{ 加密之后的结果,然后再将image.flag文件放入ida之中,搜素这5个字节,将这段数据提取出来,这段数据就是flag加密之后的结果了,分析加密过程,逆得结果
解密过程
分析代码就能找到对flag文件加密的关键代码
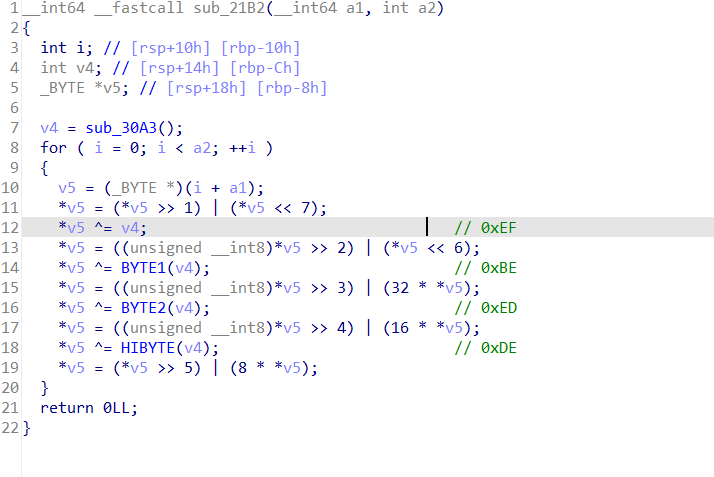
异或的对象 0xDEEDBEEF

解密脚本
1 | src = [0x00,0xD2,0xFC,0xD8,0xA2,0xDA,0xBA,0x9E,0x9C,0x26,0xF8,0xF6,0xB4,0xCE,0x3C,0xCC,0x96,0x88,0x98,0x34,0x82,0xDE,0x80,0x36,0x8A,0xD8,0xC0,0xF0,0x38,0xAE,0x40] |
NaCl
这道题可以通过动调的方式搞清楚加密的逻辑,然后来解密,但是这里是通过去 “花指令”的方式来达到目的,使得加密的过程能通过F5反编译得到
去花指令
首先通过字符串定位到程序的关键代码处
花指令的分析
其中的特殊的代码解释,这个保存到r15-8这个地址的函数,是程序接下来运行的函数

动态调试能够发现很多部分函数的结束的地方都会有这样一段代码,这段代码会在r15所指向的内存之中保存一个数组的内存地址,以及一个函数的地址,最后跳转到一个函数
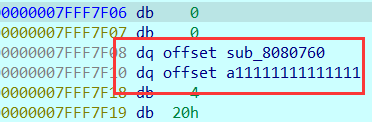
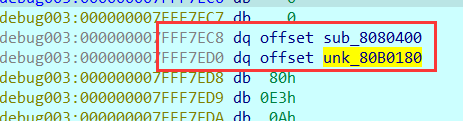
继续向下动调,发现跳转到的函数的结尾,从r15-8这个位置之中取出存放的函数的地址,并且跳转到这个函数(jmp rdi),因为跳转到的这个函数是上一个函数接下来要运行的程序,所以相当于return了
取出跳转回来的函数地址
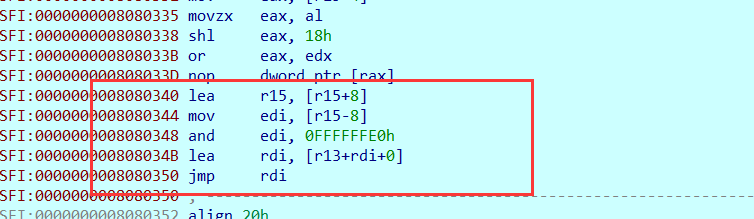
向r15-8之中存放的地址是这个函数接下来要运行的函数( 跳转到另外一个函数之后,跳转回来的地址)
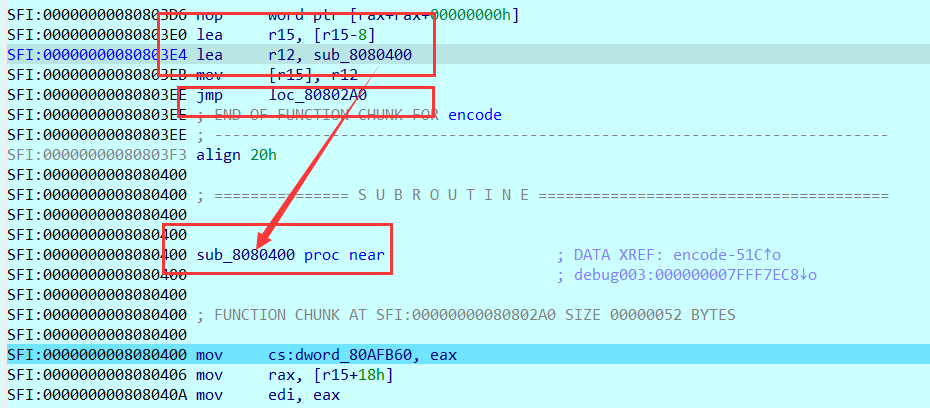
并且在每段程序之中align 10h的数据是并不运行的,是花指令,我们需要nop掉这部分的代码
idaPython去花指令
使用idapython 实现的效果
- 将r15-8之中放入函数的过程,直接nop掉(我觉得也可以不nop掉这部分的程序,我也将不nop和nop掉着部分的汇编都进行了尝试,发现都是可以的),将jmp到的函数,改为call对应的函数(call => 0xE8)
- 然后将跳转到的这个函数之中后面为了跳转回来的指令修改了成ret指令
- 将align 10h 之中的无效指令nop掉
- 将 jmp rdi 的指令转换成ret (我觉得对r15操作的指令就每必要修改了)
idaPython之中经常会用到的APT
**idc.print_insn_mnem(ea)**来获取每条指令的操作符,判断操作符是否为 call 或者 jmp
print(“0x%x %s” % (line, idc.GetDisasm(line))) 将对应地址的汇编得到
dism_addr = list(idautils.FuncItems(func)) 实际上返回的是一个迭代器,但是我们将它强制转换为 list 类型。这个 list 以一种连续的方式存储着所有指令的起始地址。
idc.next_head(line) 和 idc.prev_head(line) 获取附近指令的地址
idc.get_operand_type(ea,n) 获取操作数类型 ea 是一个地址,n 是一个索引。
操作数类型的种类

ida_ida.inf_get_min_ea() 和 ida_ida.inf_get_max_ea() 获取可执行文件的最大地址和最小地址,我们遍历了所有的函数和指令。
用来打补丁的 ida_bytes.patch_byte(ea, value) 、 ida_bytes.patch_word(ea, value)、ida_bytes.patch_dword(ea, value)、ida_bytes.patch_qword(ea, value) 这里面的 value 是替换的机器码
idc.GetOperandValue(ea, n) 获取操作数引用的地址(取值)
idc.print_operand(here(),0) 获取操作数 如rdx(取符号)
idc.print_insn_mnem(here()) 获取操作符 如 mov
idc.GetDisasm(ea) 获取汇编 如mov rdx, rdi
idc.NextHead(ea)- 返回下一条指令(无效指令算一条)
idc.PrevHead(ea)- 返回上一条指令
idc.NextAddr(ea)- 返回下一地址
idc.PrevAddr(ea)- 返回上一地址

需要处理的3个位置的汇编代码
第一种:
1 | SFI:000000000808040C lea r15, [r15-8] |
第二种:
1 | SFI:00000000080802E0 lea r15, [r15+8] ; 取地址 |
第三种nop掉的指令(第一种汇编代码之后的代码)
1 | 上面jmp之后的指令align 20h 中的数据全部nop掉 |
nop掉jmp前面的汇编代码的效果是:
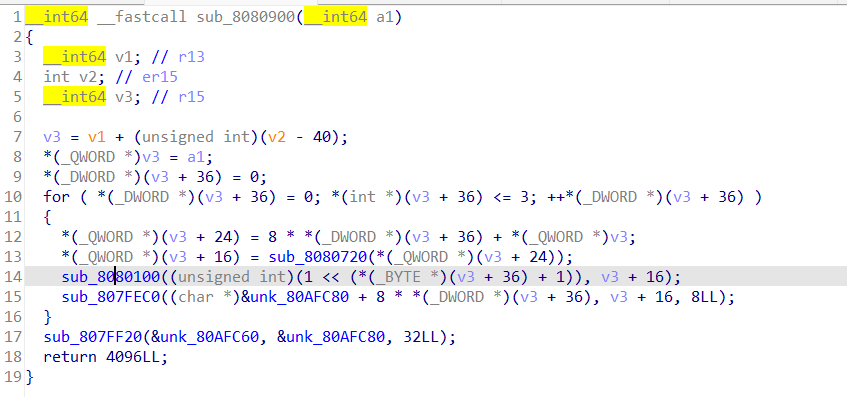
不nop掉jmp前面那部分的汇编代码的效果:
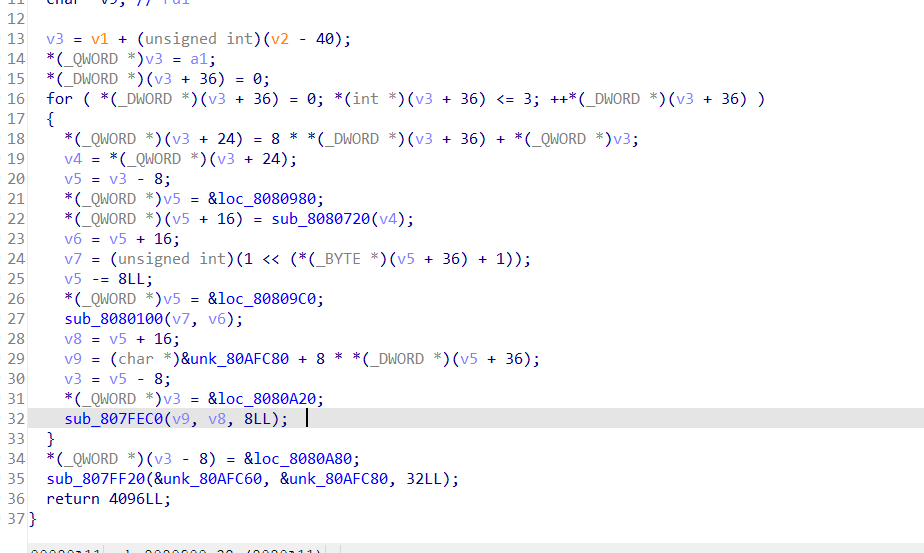
两种方式中主要的加密函数都被保存下来了,只是中间数据的展示方式是不一样的
idaPython脚本:
1 | import ida_ida |
xtae解密
这个地方的xtea的delta变了,轮数变了
加密过程分析
8个32位的数据,分成了4次加密,每次加密2个32位的数据,加密的轮数依次是 2 4 8 16

xtea的数据提取
密钥:
1 | 3020100h, 7060504h, 0B0A0908h, 0F0E0D0Ch |
密文:
1 | 0x66, 0xC2, 0xF5, 0xFD, 0x86, 0x82, 0x32, 0x7A, 0x04, 0x40, |
4次加密的轮数 2 4 8 16
xtea解密脚本
1 | #include <stdio.h> |
xtea解密之后的4个数据
1 | 0xe71f5179,0xb55f9204 |
异或操作解密
异或加密的过程分析
异或加密的函数
将异或的数据直接提取出来(动调)
v5->tailData4 的 值等于这个循环完成之后 v5->headData4 的 值,所以逆向的时候异或现在的head的这个值,这样就能够得到之前的head的值,然后将新的head的值给head,把之前的head的值给tail
要异或的数据的值是要倒着来的
将tailData的数据作为前面的4个字节 将headData的数据作为后面的4个字节 这样组成结果的8个字节
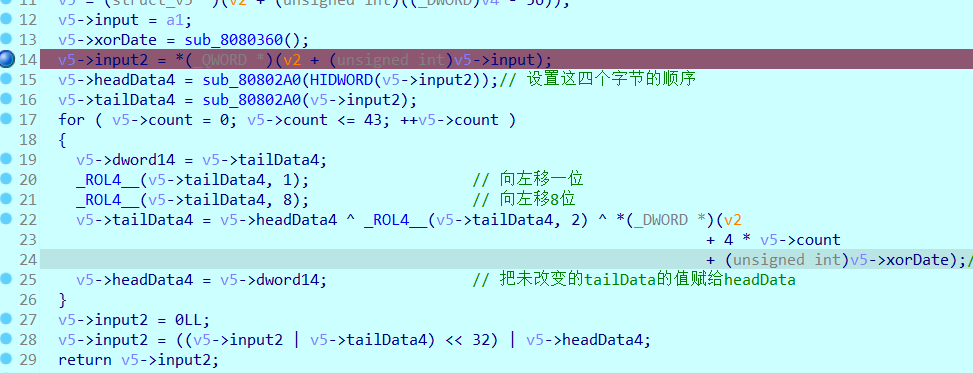
异或数据提取
通过动调的方式获得异或的对象(每4个字节为一组来取用),并且在解密的时候解密使用的异或的对象是倒着来取的
1 | 0x07, 0x06, 0x05, 0x04, 0x03, 0x02, 0x01, 0x00, 0x0F, 0x0E, |
解密脚本
逆向的时候需要注意的是 使用的src中的数是逆着取用的
1 | src = [0x04050607,0x00010203,0x0c0d0e0f,0x08090a0b,0xcd3fe81b,0xd7c45477,0x9f3e9236,0x0107f187,0xf993cb81,0xbf74166c,0xda198427,0x1a05abff,0x9307e5e4,0xcb8b0e45,0x306df7f5,0xad300197,0xaa86b056,0x449263ba,0x3fa4401b,0x1e41f917,0xc6cb1e7d,0x18eb0d7a,0xd4ec4800,0xb486f92b,0x8737f9f3,0x765e3d25,0xdb3d3537,0xee44552b,0x11d0c94c,0x9b605bcb,0x903b98b3,0x24c2eea3,0x896e10a2,0x2247f0c0,0xb84e5caa,0x8d2c04f0,0x3bc7842c,0x1a50d606,0x49a1917c,0x7e1cb50c,0xfc27b826,0x5fdddfbc,0xde0fc404,0xb2b30907] |
分析代码知道tailData是低位的数据 headData是高位的数据

并且这四个字节的排列顺序是:将input的数据的低字节放到的高字节,高字节放到了低字节

所以最后数据输出:
1 | encode = [0x4a496f62,0x6d4d3770,0x504f3652,0x73435451,0x386b4645,0x30672d4c,0x6976424e,0x78685975] |
*CTF{mM7pJIobsCTQPO6R0g-L8kFExhYuivBN}
